
I wonder if a neural network could receive radio signals?
That was the thought that led to this project. Whether you could train a model, with just radio signals and their corresponding audio, to do that conversion without knowing anything about the signals themselves.
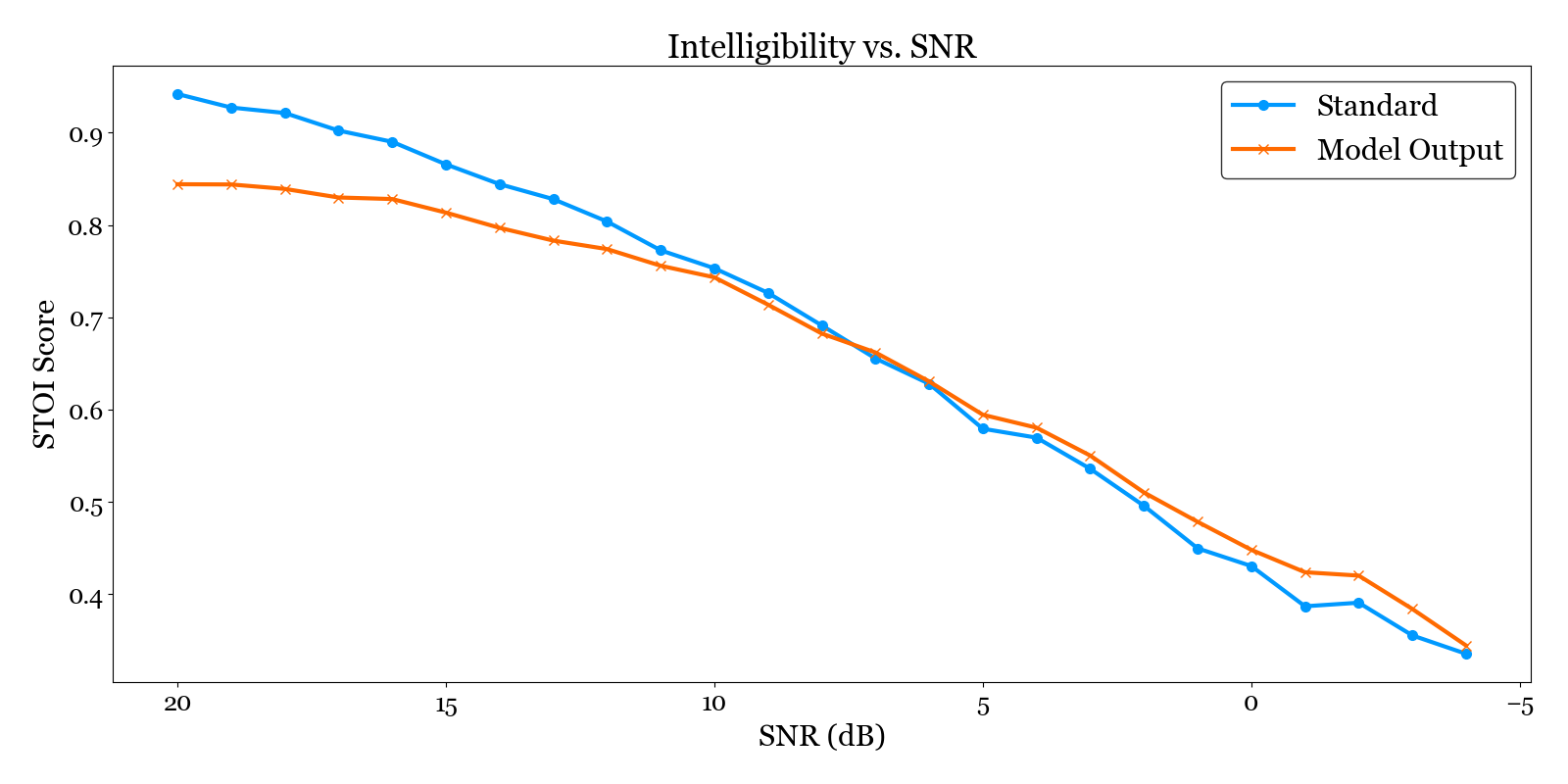
Spoiler alert: it is possible! Not only that, the network can reduce noise and enhance the audio at the same time! Here is a comparison of the model output vs. traditional demodulation on a noisy signal:
Standard Processing: Model Output:
Pretty impressive, right? Subjectively I think the model output is noticeably clearer, and this is backed up by an objective measure of speech intelligibility, showing the model consistently outperforming as noise increases (left-to-right on the chart).
The context for this project was that I had been studying neural nets, especially Andrej Karpathy’s excellent YouTube series, and wanted to try applying that knowledge to a “real” problem. This is a sort of after-action report on the main challenges and learnings. You can find the code for the project on GitHub.
While not strictly necessary, a basic understanding of software-defined radio (SDR) and amplitude modulation would help to follow along, which I cover in my previous article AM Demodulation Illustrated with visualizations and code.
Goals
The goal of this project was to get experience applying Machine Learning to a “real” problem, going through the entire process from problem analysis through to implementation, evaluation, and iteration. While I obviously hoped to get a working result, the goal was not to build a better radio.
Problem
I chose “Receiving AM Radio” as the problem for a few reasons; mainly that it seemed cool. I did have some background knowledge (having written an SDR library, and done a few SDR projects previously) that would hopefully allow me to focus more of my attention on the ML aspects. The radio aspects ended up being a challenge in their own right as you’ll see, so this foundation was definitely a factor in success.
The basic idea was to replace the traditional demodulation process with a neural network, taking in RF signal from the SDR, and outputting audio.
Feasibility Study
I started experimenting, trying basic model architectures with synthetic data, to try to get a sense of whether this was going to work at all. It did not go well:
Post by @ccostes3View on Threads
I wasn’t making much headway on my own, and decided to do some Googling and see if I could find any similar projects. I fortunately found this paper, which did almost exactly what I was trying to do, just with digital data rather than audio! Not only that, they published their code!
My architecture was surprisingly close to what they had done, which was super validating and I started to feel like maybe I had some idea of what I was doing. The key difference was that they used an autoencoder, rather than just an encoder, to process the input into a compressed embedding. This outputs a reconstructed version of the input signal based on that embedding, enabling training the encoder much more effectively than only being able to work off of the audio output.
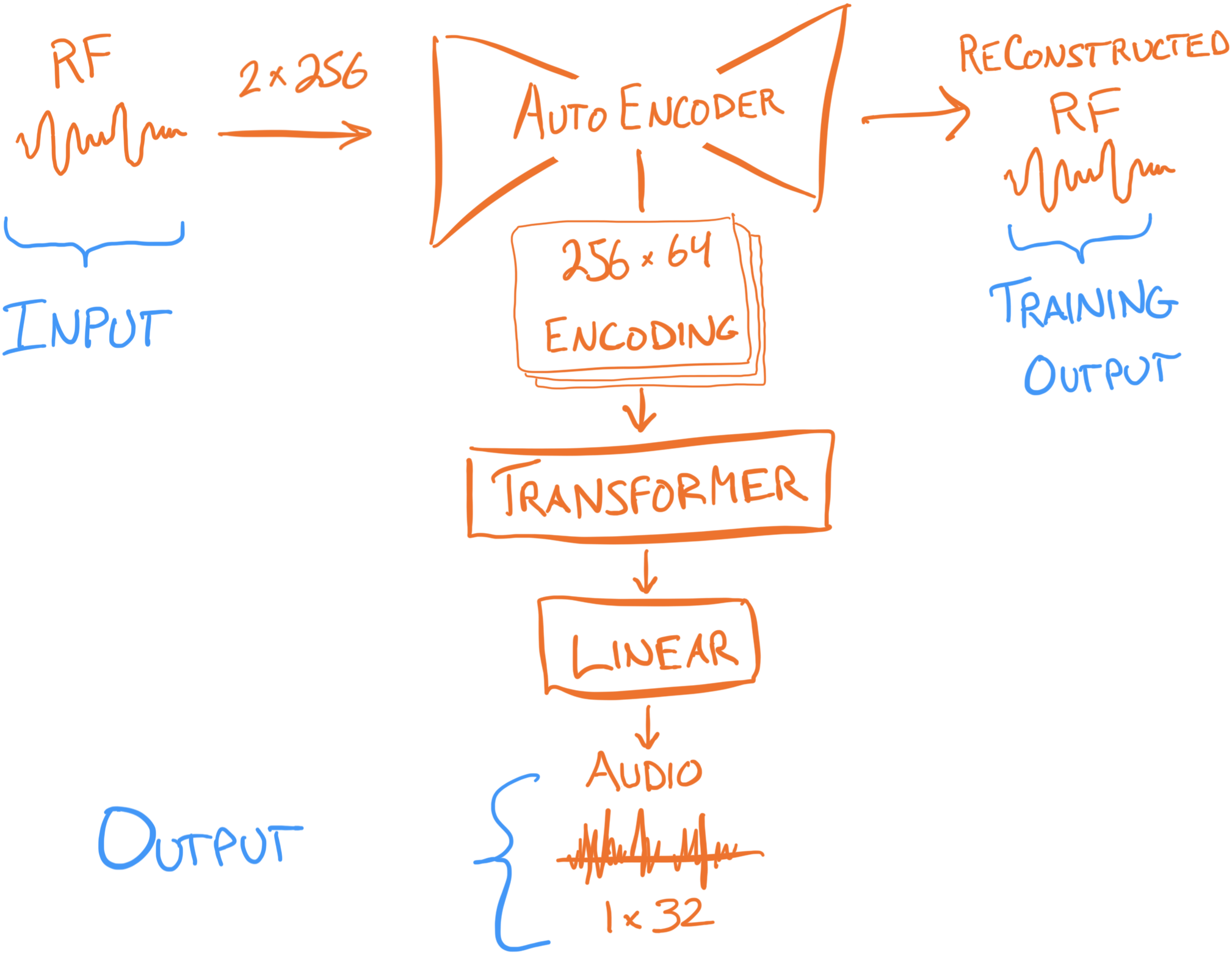
Implementing this resulted in immediate and surprising results:
Post by @ccostes3View on Threads
Real Data
At this point I knew the goal of using a neural net to receive AM radio was feasible, and shifted focus to getting this to work on a real signal. Ideally I hoped to build a system that could receive in real-time, but at least wanted to be able to play back a recorded signal.
The first issue was data rate: the real signal was at a much higher frequency than the test data in my experiments, which consequently required much higher data rates: over 2MB per second! This posed a significant challenge for real-time processing, but also for training given the large amount of data to store and transfer.
I decided that, rather than working on the raw input data from the receiver and replacing the entire demodulation process, the model would use the output of the downsampling step as its input; a much more manageable 16 kB/s of data. While a slight compromise to my ideal goal, this dramatically decreased training time and meant I could iterate much more quickly.
Debugging
The next issue was that it didn’t work. The model performed great on the training data, but produced nothing but constant tones when run on the real SDR data. I knew there had to be something wrong with my synthetic training data, and spent days carefully inspecting each step in the demodulation process trying to spot a difference with the real thing.
I finally noticed that the carrier signal (the big spike in the middle of the plot below) in the real data wasn’t being shifted to exactly 0 Hz. I wasn’t sure if this was a big deal, but decided to try manually adjusting it to see if the model would perform any better.
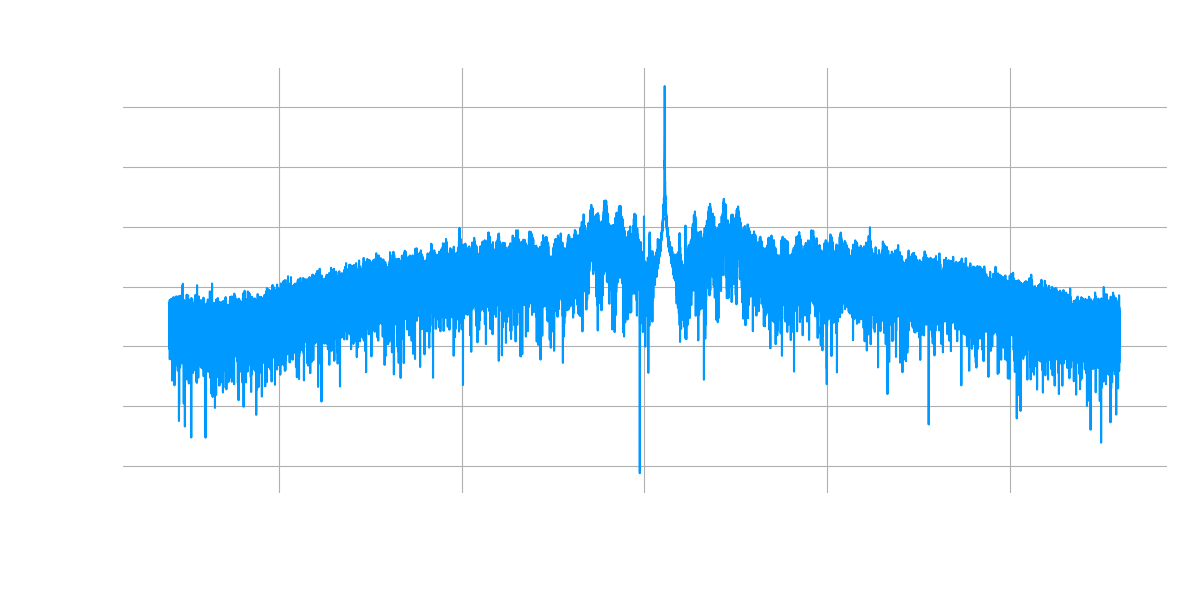
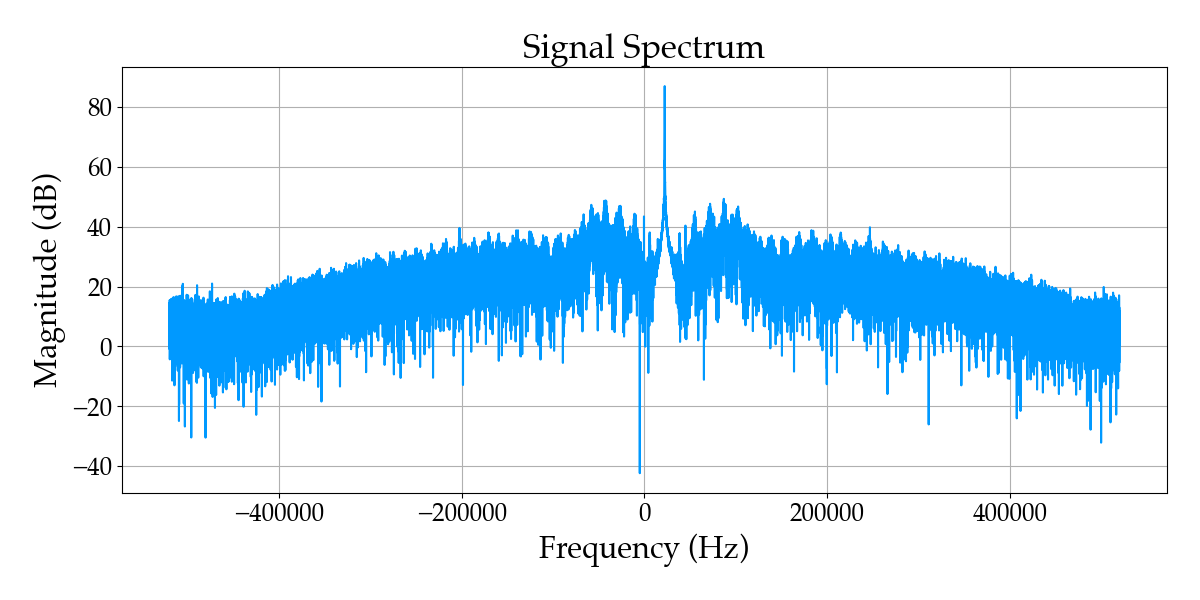
In a real “eureka!” moment, as I got the offset dialed in the baseband signal waveform started to look like audio riding along a sinusoid!
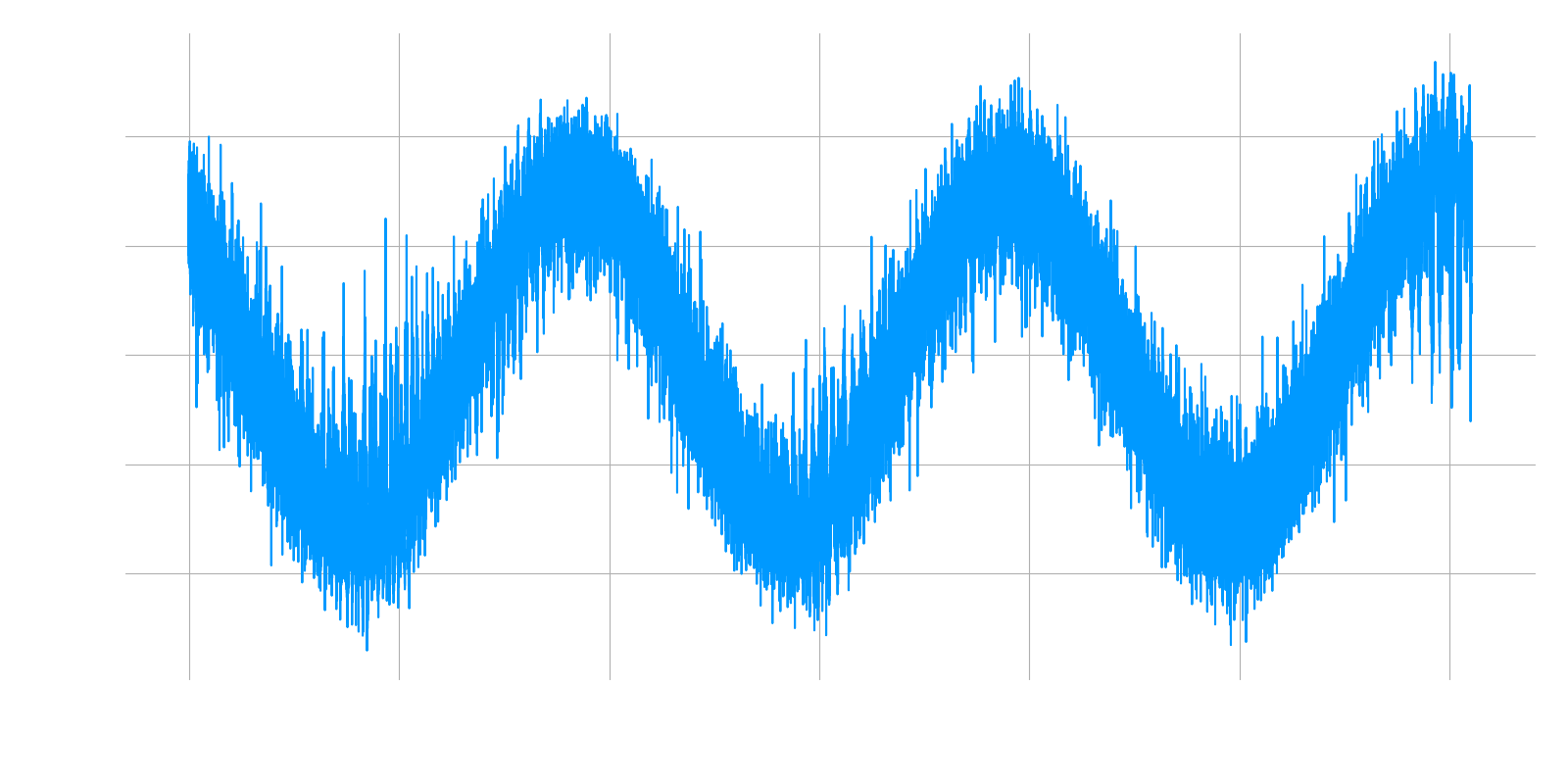
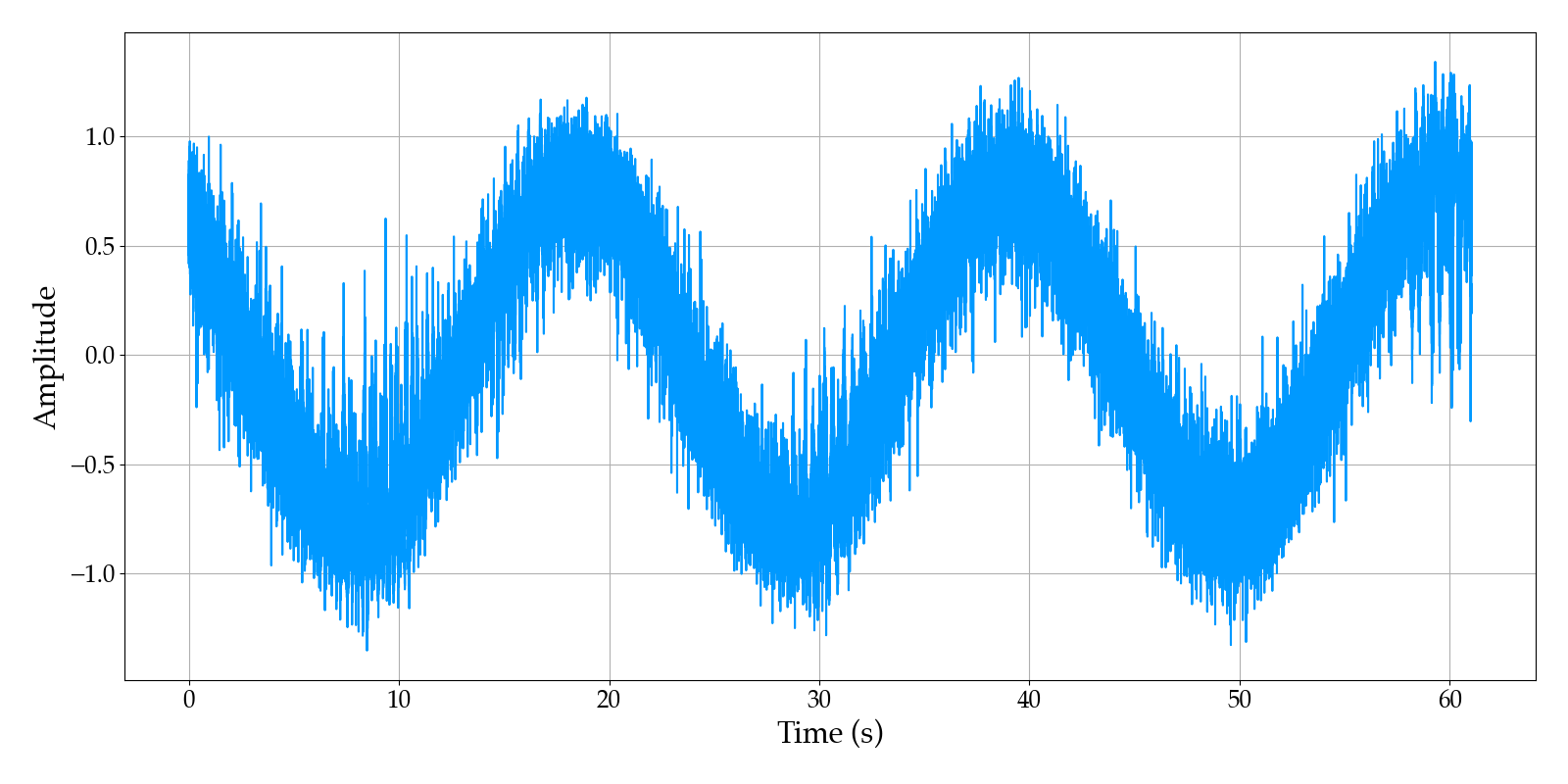
Seeing this, I was almost positive I had found the issue. Running the model on this signal, the tones were still there, but pulsing in and out was the audio!
I updated the training data to include a random frequency offset and re-trained the model, and it worked!
Bonus Challenge: De-noising
Once I had demodulation working I decided to try add a stretch goal: could the model learn to enhance a noisy signal? You already know that the answer was yes. To implement this, I added a “noise schedule” to the training that would use a noise-free signal for the first few epochs and gradually increase the amount of noise, all while evaluating loss against the “clean” version of the audio and input signal.
One interesting note is that I experimented with some audio-specific loss functions that measure frequency content, rather than the simple sample-by-sample MSE loss. My objective for the model was to produce intelligible audio, not exactly reconstruct the samples from the source, so I thought spectral-based loss functions may lead the model to learn better representations.
Unfortunately this didn’t work out, and the simple MSE loss function outperformed anything else that I tried.
Learnings
This project was a fantastic learning experience. Some key takeaways:
- Machine learning is a very iterative and empirical process - finding the best approach requires experimentation.
- Data quality is crucial. Synthetic data is a great tool, but it needs to represent the critical aspects of real-world data - make sure you understand what those aspects are!
- Start simple - even that may be harder (or easier) than you think.
- Don’t be afraid to read papers and borrow ideas.
Overall, while AM radio may not be the most practical application of ML, it served as an excellent testbed for tackling a problem end-to-end. I hope you enjoyed reading about my experience, and get inspired to try hacking on my code or tackling a problem of your own!